출처 : https://github.com/tensorflow/cleverhans
cleverhans-lab/cleverhans
An adversarial example library for constructing attacks, building defenses, and benchmarking both - cleverhans-lab/cleverhans
github.com
자율주행 자동차가 우리 생활의 전반을 차지하고 있다고 가정해보자 (멀지 않은 미래다)
자율주행자동차가 만약 여러가지 신호들을 오인식 하게 된다면 분명 인명피해로 이어질거고 이는 심각한 사회문제로 대두될 것이다.

당신의 차는 이런 상황이 오게 될 수도 있다. 당신이 자고있던 혹은 자고 있지 않던 당신의 붕붕이는 오인식으로 인해 계속 달릴 것이고 이는 큰 사고로 이어질 수도 있는 것이다!
이렇게 인공지능을 공격하는 건 무엇일까?
바로 적대적 공격! (Adversarial Attack) 되시겠다.
일단 실제 있었던 예시부터 볼까?
2016년 테슬라의 원격 주행 자동차가 해킹으로 원격조종 당하는 영상이 화제가 되었다. 중국 텐센트의 연구원들은 19km 원거리에서 주행 중인 자율주행차의 제어 네트워크를 해킹해, 자동차를 급제동시키고, 문을 열고 좌석을 움직이는 실험 결과를 유튜브에 올렸다.
테슬라 측에서는 브라우저와 와이파이 등의 취약점을 이용해야 하므로 가능성이 적다고 항변했으나 2017년 워싱턴대학의 연구팀에 의해 더 쉽게 자율주행차를 오작동시키는 방법이 시연되었습니다.
해당 연구팀은 도로 교통 표지판에 이미지 스티커를 부착해 자율주행 자동차의 표지판 인식 모듈을 교란하는 실험을 발표했다. 스티커 부착만으로 자율주행차가 ‘정지’ 표시를 ‘속도제한’표시로 오인식 하도록 만들 수 있었다.

한줄요약: 스티커 한장으로 표지판을 오인식하게 할 수 있다.
사람의 눈으로는 구별 못할 것이다. ai만 알아차리는 노이즈 픽셀 값을 추가시켜서 다르게 인식 시키는 것이다.
기존의 해킹 방법이 유무선 네트워크나 시스템, 단말기 등 기존의 취약점을 이용한 것이라면, 이 새로운 해킹 방법은 머신러닝 알고리즘이 내재하고 있는 취약점을 이용했다는 점에서 차이가 있다. 다시 말해 머신러닝 엔진이 스스로 잘못된 판단을 하도록 유도하는 방식의 공격이다.
이처럼 머신러닝 알고리즘에 내재하고 있는 취약점에 의해 적대적 환경에서 발생할 수 있는 보안 위험을 “적대적 공격(Adversarial Attack)”이라고 한다.
학습과정은 데이터 수집 + 학습용 데이터 가공 하는 데이터 준비 과정을 거친다.
적절한 데이터가 준비되면 좋은 머신러닝 알고리즘을 사용해 기계를 학습시킨다.
학습이 완료되면 이게 얼만큼의 정확성을 갖고 있는지 측정해 모델의 성능을 테스트한 후 완성된 모델을 배포한다.
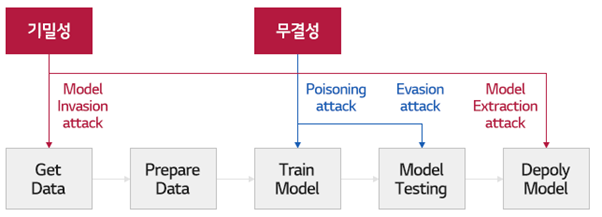
기밀성이란 sender가 보낸 메세지는 receiver 만 확인 가능하다.
무결성이란 Receiver가 받은 메세지는 Sender가 보낸 메시지와 같다
라는 뜻으로 암호학기초에서 배웠는데, 일단 이정도까지만 알면 될 듯 하다.
이러한 일련의 기계 학습 과정에서의 기밀성과 무결성을 공격하는 적대적 공격에는
1) 머신러닝 학습 과정에서 악의적인 학습 데이터를 주입해 머신러닝 모델을 망가뜨리는 중독 공격(Poisoning attack)
2) 머신러닝 모델의 추론과정에서 데이터를 교란해 머신러닝을 속이는 회피 공격(Evasion attack)
3) 역공학을 이용해 머신러닝 모델이나 학습 데이터를 탈취하는 모델 추출 공격(Model extraction attack)
4) 학습 데이터 추출 공격(Inversion attack)
등이 있다. 흠 무슨 말일까, 더 자세하게 알아보자.
1) Poisoning Attack (중독 공격, 오염 공격)
Poisoning attack은 의도적으로 악의적인 학습 데이터를 주입해 머신러닝 모델을 망가뜨리는 공격을 말하는데, 다른 머신러닝 공격 기법과 다른 점은 모델 자체를 공격해서 모델에게 영향을 준다는 점이다.

Poisoning attack은 악의적인 데이터를 최소한으로 주입해 모델의 성능을 크게 떨어뜨리는 것이 공격의 평가 기준이 되며, 의료 기계를 대상으로 한 연구 결과에서 대상 장비의 오작동을 발생시키기도 한다.
관련 논문 : Exploiting the Vulnerability of Deep Learning-Based Artificial Intelligence Models in Medical Imaging: Adversarial Attacks
다음에 꼭 리뷰하겠음.
2) Evasion attack(회피 공격)
Poisoning attack이 머신러닝 모델의 학습 과정에 직접 관여해 모델 자체를 공격하는 개념이라면 Evasion attack은 입력 데이터에 최소한의 변조를 가해 머신러닝을 속이는 기법이다.
이미지 분류 머신러닝의 경우, 사람의 눈으로는 식별하기 어려운 방식으로 이미지를 변조해 머신러닝 이미지 분류 모델이 착오를 일으키게 만드는 수법이다. 앞서 언급한 자율주행차에 적용된 공격 방식이 바로 Evasion attack이다.
Evasion attack에 의해 아래와 같이 팬더 이미지에 사람의 눈으로는 분간하기 어려운 노이즈를 추가하면 머신러닝이 이를 긴팔원숭이로 착각하게 만드는 것이 가능하다.

앞서 언급한 자율주행차 해킹과 마찬가지 방식으로, 2018년 구글 리서치 그룹은 논문을 통해 이미지 인식 머신러닝 알고리즘을 오작동 시킬 수 있는 스티커를 발표했다.
적대적 스티커(Adversarial patch)라고 불리는 이 스티커를 바나나 옆에 붙이면 이미지 인식 앱이 바나나를 100% 확률로 토스터 기기로 인식했다. 이 스티커는 누구나 쉽게 인쇄해 사용할 수 있고 악의적인 공격인지 쉽게 발견하기 어려워서, 악용되는 경우 큰 위험을 가져올 수도 있다.
이런 공격 방식이 실생활에 이용된다면 보안 솔루션의 탐지 정책을 우회하거나, 교통 신호를 교란시켜 자율주행 차량의 오작동을 유발하고 생체인식 시스템을 우회하는 등의 심각한 문제가 예상된다.
3) Inversion attack (전도 공격, 학습 데이터 추출 공격)
머신 러닝 모델에 수많은 쿼리를 던진 후, 산출된 결과값을 분석해 모델 학습을 위해 사용된 데이터를 추출하는 공격이다.

Inversion attack을 이용하면 얼굴 인식 머신러닝 모델의 학습을 위해 사용한 얼굴 이미지 데이터를 복원할 수도 있다. 데이터 분류를 위한 머신러닝은 주어진 입력에 대한 분류 결과와 신뢰도를 함께 출력하게 되는데, Inversion attack은 이때 출력된 결과값을 분석해 학습 과정에서 주입된 데이터를 복원하는 방식이다.
머신러닝 모델을 훈련시키는 학습 데이터 안에 군사적으로 중요한 기밀정보나 개인정보, 민감정보 등이 포함되어 있는 경우라면, Inversion Attack을 이용한 공격에 의해 유출될 가능성이 존재한다 => 데이터를 추출해 악용 할 수 있다는 것
4) 적대적 공격에 대한 방어법
적대적 공격에 대한 방어 기법으로는 먼저, 가능한 모든 적대적 사례를 학습 데이터에 포함해 머신러닝을 훈련시키는 적대적 훈련(Adversarial training)이 있다. 머신러닝을 훈련시키는 단계에서 예상 가능한 해킹된 데이터를 충분히 입력해 머신러닝의 저항성을 기르는 방식이다.
학습모델의 결과값 분석을 통해 모델을 추론하는 방식의 공격을 차단하기 위해, 학습모델의 결과값이 노출되지 않도록 하거나, 결과값을 분석할 수 없게 변환하는 방식으로 공격을 차단할 수도 있다.
또한, 적대적 공격 여부를 탐지해 차단하는 방법도 연구되고 있다. 원래의 모델과 별도로 적대적 공격 여부를 판단하기 위한 모델을 추가한 후, 두 모델의 추론 결과를 비교해 두 결과 간에 큰 차이가 발생하는 경우 적대적 공격으로 탐지하는 방식이다.
그 외에도 모델에 반복적인 쿼리를 시도하는 Inversion attack이나 Model extraction attack을 방어하기 위해서 모델에 대한 쿼리 횟수를 제한하는 방식도 고려될 수 있다. 학습 데이터에 포함된 기밀정보, 민감정보가 노출되지 않도록 암호화 등의 비식별 처리 방식도 연구되고 있다.
구글은 적대적 공격 및 방법 기법들을 연구하는 자사의 오픈소스 소프트웨어 라이브러리에 ‘CleverHans’라는 이름을 붙였다.
'머신러닝-딥러닝 > 논문리뷰' 카테고리의 다른 글
| GAN: Generative Adversarial Networks - 동빈나 유튜브 리뷰 (0) | 2020.12.29 |
|---|---|
| 적대적 공격 -1) ArtBreeder 이슈 정리, 인공지능의 차별과 편견 (0) | 2020.12.23 |