220119
1. torch.autograd
자동 미분을 위한 함수들이 포함되어져 있습니다. 자동 미분의 on/off를 제어하는 콘텍스트 매니저(enable_grad/no_grad)나 자체 미분 가능 함수를 정의할 때 사용하는 기반 클래스인 'Function' 등이 포함되어져 있습니다.
#가중치를 업데이트 하기 위해선 자동 미분을 해줘야겠죠잉~? 그걸 도와주는 것임
2. torch.nn
신경망을 구축하기 위한 다양한 데이터 구조나 레이어 등이 정의되어져 있습니다. 예를 들어 RNN, LSTM과 같은 레이어(layer), ReLU와 같은 활성화 함수(activation function), MSELoss와 같은 손실 함수(loss function)들이 있습니다.
3. torch.onnx
ONNX(Open Neural Network Exchange)의 포맷으로 모델을 익스포트(export)할 때 사용합니다. ONNX는 서로 다른 딥 러닝 프레임워크 간에 모델을 공유할 때 사용하는 포맷입니다.
ex) 서로다른 프레임워크 간에도 weights 나 bias를 공유할 수 있음
4. 미분을 하기 위해선 꼭 torch에선 tensor의 형식으로 들어가줘야함.

@@5. 3d CNN
RGB 값을 넣음. 각 채널로 넣음(의료영상에서 사용하는 것 같기도 하고)
이건 아직도 이해가 안됨
6. PyTorch Tensor Shape Convention
사실 딥 러닝을 할때 다루고 있는 행렬 또는 텐서의 크기를 고려하는 것은 항상 중요합니다. 여기서는 앞으로 행렬과 텐서의 크기를 표현할 때 다음과 같은 방법으로 표기합니다. 앞으로 다루게 될 텐서 중 가장 전형적인 2차원 텐서를 예로 들어볼까요?
* 2D Tensor(Typical Simple Setting)
|t| = (Batch size, dim) #dim은 차원입니다.

위의 경우는 2차원 텐서의 크기 |t|를 (batch size × dimension)으로 표현하였을 경우입니다. 조금 쉽게 말하면, 아래의 그림과 같이 행렬에서 행의 크기가 batch size, 열의 크기가 dim이라는 의미입니다.
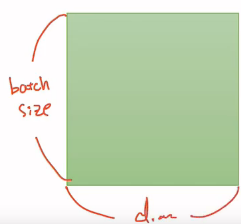
- 훈련 데이터 하나의 크기를 256이라고 해봅시다. [3, 1, 2, 5, ...] (dim은 1이지만 안의 값들이 256이져)
- 이런 숫자들의 나열이 256의 길이로 있다고 상상하면됩니다. 다시 말해 훈련 데이터 하나 = 벡터의 차원은 256입니다. 만약 이런 훈련 데이터의 개수가 3000개라고 한다면, 현재 전체 훈련 데이터의 크기는 3,000 × 256입니다. 행렬이니까 2D 텐서네요. 3,000개를 1개씩 꺼내서 처리하는 것도 가능하지만 컴퓨터는 훈련 데이터를 하나씩 처리하는 것보다 보통 덩어리로 처리합니다. 3,000개에서 64개씩 꺼내서 처리한다고 한다면 이 때 batch size를 64라고 합니다. 그렇다면 컴퓨터가 한 번에 처리하는 2D 텐서의 크기는 (batch size × dim) = 64 × 256입니다.
* 3D Tensor(Typical Computer Vision) - 비전 분야에서의 3차원 텐서
|t| = (batch size, width, height)

일반적으로 자연어 처리보다 비전 분야(이미지, 영상 처리)를 하시게 된다면 좀 더 복잡한 텐서를 다루게 됩니다. 이미지라는 것은 가로, 세로라는 것이 존재합니다. 그리고 여러 장의 이미지, 그러니까 batch size로 구성하게 되면 아래와 같이 3차원의 텐서가 됩니다.
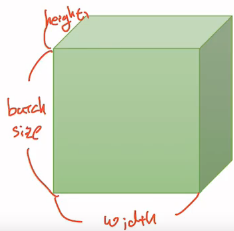
위의 그림은 세로는 batch size, 가로는 너비(width), 그리고 안쪽으로는 높이(height)가 되는 것을 보여줍니다.
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6.])
0., 인 이유: 0.0 임을 생략
7. view,unsqueeze,squeeze
차원조절함수들
Pytorch에서 텐서의 shape를 변환하고 차원을 확장할 때는 view() 함수를 사용, tensorflow의 reshape() 함수와 유사
squeeze() 함수와 unsqueeze() 함수 역시 차원을 변환하는 함수,
squeeze() 함수는 원소가 1인 차원을 제거,
unsqueeze() 함수는 인자로 받은 숫자로 특정 위치에 1인 차원을 추가할 수 있습니다.
- view() 함수
a.view(3,4,1)
- squeeze() 함수
a.view(3,4,1).squeeze()
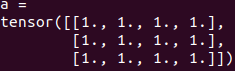
- unsqueeze() 함수
a.unsqueeze(0)
a.unsqueeze(0).size()
a.unsqueeze(2)
a.unsqueeze(2).size()
8. 코드 실습 (뒤로빼겠음)
9. 벡터 연산으로 이해하기
행렬의 곱셈 과정에서 이루어지는 벡터 연산을 벡터의 내적(Dot Product)이라고 합니다.
H(X)=w1x1+w2x2+w3x3
위 식은 아래와 같이 두 벡터의 내적으로 표현할 수 있습니다.

두 벡터를 각각 X와 W로 표현한다면, 가설은 다음과 같습니다.
H(X)=XW
x의 개수가 3개였음에도 이제는 X와 W라는 두 개의 변수로 표현된 것을 볼 수 있습니다.
10. 모델을 클래스로 구현하기
1. 순전파(forward propagation)
순전파(forward propagation)은 뉴럴 네트워크 모델의 입력층부터 출력층까지 순서대로 변수들을 계산하고 저장하는 것을 의미합니다. 딥러닝이 학습을 하면서 자신만의 답을 출력하는 과정이다. 모델에서 정답을 뽑아내는 과정이라고 볼 수 있다.
2. backpropagation(역전파)란 무엇인가?
딥러닝은 계속계속 시행착오를 겪어 나가면서 학습해나가는 모델이다. 그렇다면, 완전히 학습이 되기 전까지는 계속계속 틀리는 과정을 거친다는 이야기이다. 그렇게 딥러닝은 순전파에서 틀리는 정답을 토대로 실제 답과 비교해나가면서 학습을 하게 된다. 그래서 모델의 파라미터(weight와 bias)를 결정하게 된다. 그렇다면 파라미터는 어떻게 결정할까? 신경망이 뱉은 예측값과 실제값의 오차가 모든 데이터를 대상으로 최소가 되도록 결정하면 된다.
그레디언트(gradient)란 벡터가 error space에서 가장 급격하게 에러가 증가하는 방향성 을 나타낸다.
그레디언트는 cost를 w로 편미분해서 구한다. 편미분을 모르시는 분들은 편하게 미분이라고 생각해도 무방하다.
그렇다면 미분이란 무엇인가? 여기서 그것을 증명하거나 나타내보이진 않겠지만.. (궁금하면 찾아보시라)
예를들어 a를 b로 미분한 값은 b를 조금만 +로 움직였을 때 a가 +로 간다는 뜻이다. 즉,
cost를 w로 미분했다는 뜻은 w를 아주 조금 +로 움직였을 때 c가 +로 간다는 뜻이다.
그러므로 cost를 w로 미분한 값의 반대 방향은(- 방향) cost를 낮추는 방향임을 알 수 있다.
그렇게 그레디언트의 반대 방향으로 계속해서 가며, w를 갱신해 주어야 한다는 것이다.
식으로 나타내면 위와 같은 식이 된다. w에 그레디언트를 빼주면서 업데이트가 되는데 앞에 붙은 앱실론은 learning rate라고 불리며 이 learning rate 조절을 optimizer로 한다.
생각같아서는 비용 cost를 w로 바로 미분을 해버리고 싶다. 하지만 그렇게 하면 수학적으로 매우 연산이 어렵고 복잡하다고 한다.
(제가 수학전공이 아니어서 정확하게 증명은 못하겠지만 그렇다고 하네요..!)
그래서 우리는 chain rule을 써서 단계적으로 해보도록 한다. (이것을 오차역전파법 이라고 한다.)
이 인용의 출처 :https://m.blog.naver.com/jesusss91/221616844641
=> 정리하면 optimizer는 gradient descent를 위해쓴다 gradient descent는 coss function의 최소화를 위함이고
앞서 단순 선형 회귀 모델은 다음과 같이 구현했었습니다.
# 모델을 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1.
model = nn.Linear(1,1)
이를 클래스로 구현하면 다음과 같습니다.
class LinearRegressionModel(nn.Module): # torch.nn.Module을 상속받는 파이썬 클래스
def __init__(self): #
super().__init__()
self.linear = nn.Linear(1, 1) # 단순 선형 회귀이므로 input_dim=1, output_dim=1.
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
위와 같은 클래스를 사용한 모델 구현 형식은 대부분의 파이토치 구현체에서 사용하고 있는 방식으로 반드시 숙지할 필요가 있습니다.
- 클래스(class) 형태의 모델은 nn.Module 을 상속받습니다.
- 그리고 __init__()에서 모델의 구조와 동작을 정의하는 생성자를 정의합니다.
이는 파이썬에서 객체가 갖는 속성값을 초기화하는 역할로, 객체가 생성될 때 자동으호 호출됩니다. super() 함수를 부르면 여기서 만든 클래스는 nn.Module 클래스의 속성들을 가지고 초기화 됩니다. foward() 함수는 모델이 학습데이터를 입력받아서 forward 연산을 진행시키는 함수입니다. 이 forward() 함수는 model 객체를 데이터와 함께 호출하면 자동으로 실행이됩니다. 예를 들어 model이란 이름의 객체를 생성 후, model(입력 데이터)와 같은 형식으로 객체를 호출하면 자동으로 forward 연산이 수행됩니다.
- H(x) 식에 입력 x로부터 예측된 y를 얻는 것을 forward 연산이라고 합니다.
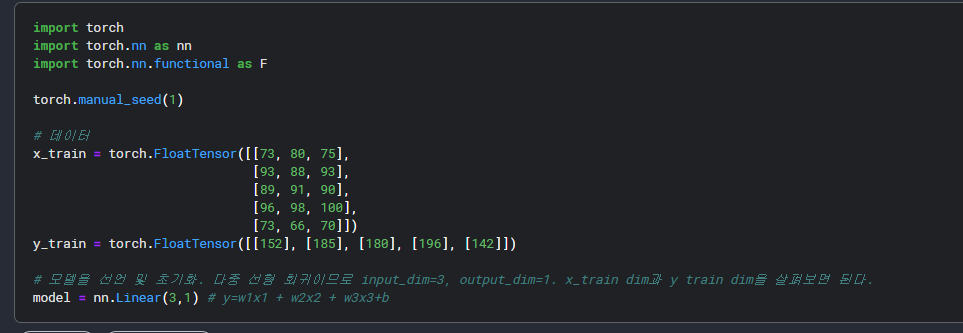
앞서 다중 선형 회귀 모델은 다음과 같이 구현했었습니다.
# 모델을 선언 및 초기화. 다중 선형 회귀이므로 input_dim=3, output_dim=1.
model = nn.Linear(3,1)
이를 클래스로 구현하면 다음과 같습니다.
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 다중 선형 회귀이므로 input_dim=3, output_dim=1.
def forward(self, x):
return self.linear(x)
model = MultivariateLinearRegressionModel()8. code



참조: https://wikidocs.net/60036,https://dreamofadd.tistory.com/112
05. 클래스로 파이토치 모델 구현하기
파이토치의 대부분의 구현체들은 대부분 모델을 생성할 때 클래스(Class)를 사용하고 있습니다. 앞서 배운 선형 회귀를 클래스로 구현해보겠습니다. 앞서 구현한 코드와 다른 ...
wikidocs.net
'머신러닝-딥러닝 > study' 카테고리의 다른 글
| 0121_Pandas (0) | 2022.01.22 |
|---|---|
| 0120_DL study (Finetuning,pretrained,Pseudo labeling,tta) (0) | 2022.01.20 |
| Loss Function 정리 (0) | 2022.01.19 |
| [pytorch] 파이토치로 시작하는 Image Segmentation (1) (0) | 2021.12.16 |
| 1. 머신러닝,딥러닝 개요 (0) | 2021.04.29 |